

In the era of machine learning and natural language processing (NLP), it’s essential to convert human language into a format that machines can understand. Embeddings are a powerful technique for transforming text—whether words, sentences, or entire documents—into dense vector representations that preserve semantic meaning. This article explores different types of embeddings, their real-world applications, and how they form the foundation of modern NLP tasks like sentiment analysis, chatbots, and search engines.
What Are Embeddings?
Embeddings are numerical representations of text in a continuous vector space where similar meanings are placed closer together. They help machines interpret relationships and semantics in human language beyond mere words.
Types of Text Embeddings
Word Embeddings
- Represent each word as a fixed-size vector.
- Examples: Word2Vec, GloVe, FastText
from gensim.models import Word2Vec
sentences = [["cat", "sits", "on", "mat"], ["dog", "plays", "with", "ball"]]
model = Word2Vec(sentences, vector_size=50, window=3, min_count=1, sg=1)
print(model.wv["cat"])
Subword Embeddings
- Break words into smaller units to better handle rare or misspelled words.
- Example: FastText
from gensim.models import FastText
model = FastText(sentences, vector_size=50, window=3, min_count=1)
print(model.wv["playing"])
Sentence Embeddings
- Represent an entire sentence as a single vector, capturing syntax and context.
- Examples: Universal Sentence Encoder, SBERT
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentence = "This is an example sentence."
embedding = model.encode(sentence)
print(embedding)
Document Embeddings
- Capture the meaning of longer texts such as paragraphs or full documents.
- Examples: Doc2Vec, Transformer-based models
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
documents = [TaggedDocument(["human", "interface", "computer"], [0]),
TaggedDocument(["survey", "user", "computer", "system"], [1])]
model = Doc2Vec(documents, vector_size=50, window=2, min_count=1, workers=4)
print(model.infer_vector(["human", "computer"]))
Contextual Embeddings
- Vector of a word changes depending on the surrounding context.
- Examples: ELMo, BERT, RoBERTa
from transformers import BertTokenizer, BertModel
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
inputs = tokenizer("The bank was flooded after the storm.", return_tensors="pt")
outputs = model(**inputs)
cls_embedding = outputs.last_hidden_state[0][0]
print(cls_embedding)
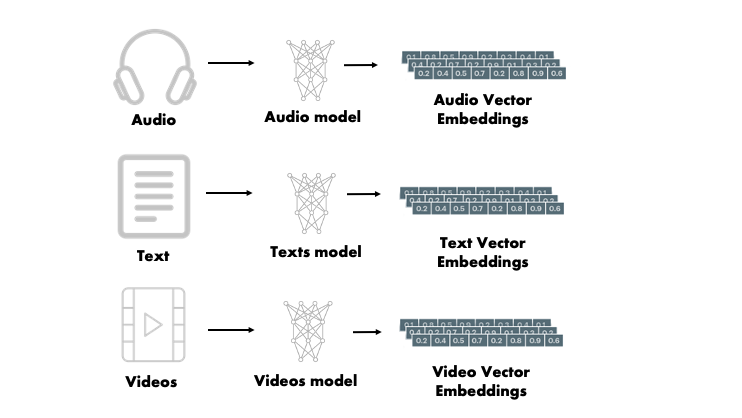
So far we understand that embeddings in the context of Large Language Models (LLMs) refer to dense vector representations of data, allowing models to understand and process complex relationships between words, images, audio, and other types of information. These embeddings transform raw data into a mathematical format that LLMs can efficiently utilize.
For you to have a view, here are Types of Non-Text Embeddings
While text embeddings are commonly used for natural language understanding, non-text embeddings also exist:
- Image Embeddings – Represent visual features of an image for tasks like classification or captioning.
- Audio Embeddings – Convert sound waves into structured numerical data for speech recognition or music analysis.
- Graph Embeddings – Encode nodes and edges in graph-based data structures for social network analysis or recommendation systems.
- Sensor Data Embeddings – Useful for IoT applications, representing environmental data like temperature, motion, etc.
- Protein/Genomic Embeddings – Convert biological sequences into vector form for applications in drug discovery.
Where We Use Which Text Embeddings
| Use Case | Embedding Type |
|---|---|
| Text classification | Word, Sentence, Document |
| Semantic search | Sentence, Document |
| Chatbots / Dialogue systems | Sentence, Contextual |
| Named Entity Recognition (NER) | Word, Contextual |
| Machine translation | Word, Sentence |
| Text summarization | Document, Sentence |
| Sentiment analysis | Word, Sentence |
How to Optimize Embeddings
- Fine-tune on your domain: Improves relevance for domain-specific text.
- Dimensionality reduction: Use PCA or t-SNE for faster processing.
- Use subwords: Handle rare or new words with FastText.
- Use contextual embeddings: For deeper understanding of meaning.
- Experiment with pooling: Try CLS token, mean pooling, or max pooling.
Text embeddings have revolutionized how machines understand human language by capturing context and meaning in numerical form. Whether you’re building a simple text classifier or a complex conversational AI, choosing the right embedding technique can significantly impact performance. As models become more context-aware and efficient, learning to apply and optimize embeddings will remain a key skill for any NLP practitioner.
![]()

Dr. Amit is a seasoned IT leader with over two decades of international IT experience. He is a published researcher in Conversational AI and chatbot architectures (Springer & IJAET), with a PhD in Generative AI focused on human-like intelligent systems.
Amit believes there is vast potential for authentic expression within the tech industry. He enjoys sharing knowledge and coding, with interests spanning cutting-edge technologies, leadership, Agile Project Management, DevOps, Cloud Computing, Artificial Intelligence, and neural networks. He previously earned top honors in his MCA.

